تا بحال بارها راجع به فناوري تبديل گفتار به نوشتار و كاربردهاي آن در مقالات مختلف صحبت كرده ايم و در مورد دستيارهاي صوتي كه از فناوري تبديل گفتار به نوشتار نيز در آن ها استفاده مي شوند و لزوم استفاده از آن ها در اپليكيشن ها نيز صحبت كرديم. اما امروز به طور اختصاصي مي خواهيم به اين مسئله بپردازيم كه فناوري تبديل گفتار به نوشتار چگونه كار مي كند و چطور يك ماشين مي تواند صوت گفتاري را به نوشتار آن تبديل كند.
تبديل گفتار به نوشتار چيست؟
فناوري تبديل گفتار به نوشتار در حقيقت زير مجموعه اي از فناوري پردازش يا بازشناسي گفتار يا speech recognition مي باشد كه مي تواند صوتي كه وجود دارد را (اعم از صحبت هاي افراد، صوت ضبط شده، صداي يك فيلم و…) به نوشتار تبديل كند يا به عبارتي گفتار را تبديل به نوشتار نمايد.
فناوري تبديل گفتار به نوشتار در حقيقت نوعي برنامه، اپليكيشن، نرم افزار و… مي باشد كه محتواي صوتي را گرفته و با پردازش محتواي آن صوت، آن را به كلمات مكتوب تبديل مي نمايد. فناوري تبديل گفتار به نوشتار، همان طور كه گفته شد يك فناوري بر پايه هوش مصنوعي مي باشد كه قادر است از يك گفت و گوي شفاهي و محتواي صوتي موجود، محتواي متني تهيه كند و يا اينكه به صورت تايپ در لحظه به كار رود.
تبديل گفتار به نوشتار چگونه كار مي كند؟
تبديل گفتار به نوشتار بخشي از فناوري بازشناسي گفتار مي باشد كه به سادگي ميتوان مسئله بازشناسي گفتار را در اين فرمول احتمالاتي شرطي خلاصه كرد:

به اين معني كه ما به دنبال رشتهاي از كلمات خروجي هستيم كه با توجه به سيگنال ورودي موجود، محتملترين رشته كلمات خروجي را به ما نشان دهند. مسئله را مي توان بر اساس اين فرمول باز كرد و گفت كه احتمال سيگنال، نسبت به رشته كلمات مورد نظر ضرب در احتمال كلمات. زماني كه اين دو را باز كنيم، در واقع دو پايه اساسي يك سيستم بازشناسي گفتار به دست مي آيد كه عبارتند از:
۱.مدل آكوستيكي
۲.مدل زباني
كار مدل آكوستيكي آن است كه تشخيص مي دهد با توجه به سيگنال ورودي محتمل ترين آواهاي خروجي چه چيزهايي هستند. كار مدل زباني هم آن است كه تشخيص دهد پس از تركيب آواها، محتمل ترين كلماتي كه در آن زبان مي توانيم پشت سرهم داشته باشيم، چه هستند. اين فرمول شايد ساده ترين و پايهاي ترين فرمول بازشناسايي گفتار باشد. در ساختار كلي يك سيستم بازشناسايي گفتار همه چيز از سيگنال صوتي شروع مي شود.
سيگنال صوتي وارد يك سري پيش پردازش ها مي شود. به عنوان مثال در زمانهايي كه سكوت داريم، سيگنال صوتي را مي بُريم يا نويز را كاهش مي دهيم، استخراج ويژگي ها نيز بخشي از پيش پردازش مي باشد. پس از اتمام پيش پردازش، سيگنال صوتي با يك سري ويژگي هاي كلي بدست ميآيد. در نهايت با تركيب دو مدل زباني و آكوستيكي، سيگنال يا ويژگي ها را به كلمات نهايي رمز گشايي (Decode) مي كنيم.

روش هاي بازشناسايي گفتار
به صورت كلي تلاشها يا روشهايي كه در زمينه پردازش گفتار شده را ميتوان به ۳ مقطع زماني تقسيم كرد:

مدل گاوسين-مدل مخفي ماركف
مدلهاي مخلوط گاوسين-مدل مخفي ماركف كه به Gmm-Hmm نيز معروف مي باشند،تا حدود 25 سال پيش بدون هيچ رقيب ديگري براي بازشنايايي گفتار استفاده مي شدند تا زماني كه در مقاله معروف سال ۲۰۰۶ كه توسط يكي از افراد يسيار مهم در زمينه deep learning يعني دكتر هينگتون ارائه شد، شبكه هاي عصبي باور عميق يا DBN ها جايگزين مدل مخلوط گاوسين شدند. اما با اين حال باز هم از مدل مخفي ماركف براي شبيه سازي زماني استفاده ميكرديم. در نهايت، طي سالهاي اخير مدل سرتاسري شبكههاي عميق بازگشتي معرفي شدند كه دو مدل قبلي را باهم تركيب كرده و در يك شبكه عميق به كار مي بردند.
شماتيك كلي اين مدل ها را در مي توانيم در تصوير زير مشاهده كنيم. براي توضيح مختصر تصوير مي توانيم بگوييم كه ما در اين مدل از سيگنال هاي صوتي كه داريم يكسري ويژگي استخراج مي كنيم. اين ويژگي ها ميتوانند expectogram يا nfcc باشند. با كمك مدل مخلوط گاوسين، يك آكوستيك مدلي را درست مي كنيم و سپس از خروجي همان آكوستيك مدل، يا در واقع از آواهايي كه بدست آمده در يك شبكه HMM، از آواهايي كه وجود داشتندمدلسازي زماني انجام مي دهيم و در نهايت به متن ميرسيم.
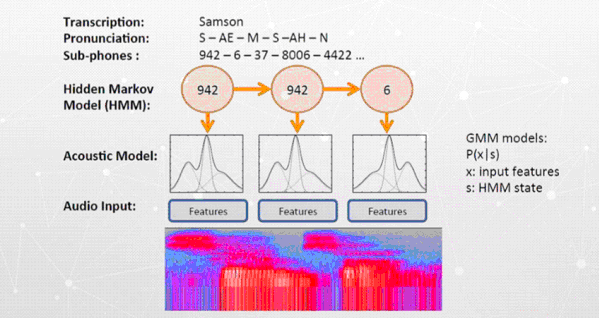
ساختار مدل شبكه عصبي باور عميق-مدل مخفي ماركف
در شبكه هاي باور عميق نيز همان اتفاق مي افتد. ما ميتوانيم expectogram و يا حتي ورودي خام سيگنال صوتي و MCC را داشته باشيم.تنها تفاوت آن با مدل قبلي آن است كه بجاي مدل گاوسين، از يك شبكه باور عميق استفاده مي كنيم.
تا قبل ۲۰۰۶ امكان اموزش شبكه هاي بزرگ وجود نداشت، در آن زمان همه ي افراد فعال در حوزه هوش مصنوعي مي دانستند كه با افزايش تعداد لايهها قاعدتا مي توانيم نتايج بهتري بگيريم و به اصطلاح به درك بالاتري از آن ورودي مي رسيم. يعني هرچه تعداد لايه ها زيادتر و عميق تر باشد ما ميتوانيم در عمق بيشتر درك بهتري از ورودي پيدا كنيم. اما امكان اموزش اين شبكه ها به دو دليل وجود نداشتهاست: اولين دليل اينكه براي انجام اين كار الگوريتمي وجود نداشته است و تا آن زمان ما تنها مي توانستيم شبكه هاي ۲ تا ۳ لايه را آموزش دهيم.زماني كه عمق شبكه ها بيشتر مي شد نيز از روش نشر بازگشتي استفاده مي كرديم كه توانايي انجام درست اين كار را نداشت.
با اين حال در سال ۲۰۰۶ الگوريتمي درست شد كه با كمك آن مي توانستند لايه ها را تك تك آموزش بدهند و سپس اين لايه ها را بر روي هم سوار كردند و در نهايت به شبكه يك آموزش كلي داده شد. بعد از اين اتفاق امكان آن به وجود آمد كه به عنوان مثال بتوانيم ۶ تا ۷ لايه از شبكه هاي عصبي را با دقت خوبي آموزش دهيم. با آمدن اين الگوريتم جاي مدل مخلوط گاوسين يا GMM ها با شبكه هاي باور عميق يا DBM تغيير كرد، اما ما همچنان از HMM ها يا مدل ماركف براي شبيه سازي مدل هاي زماني استفاده مي كرديم.
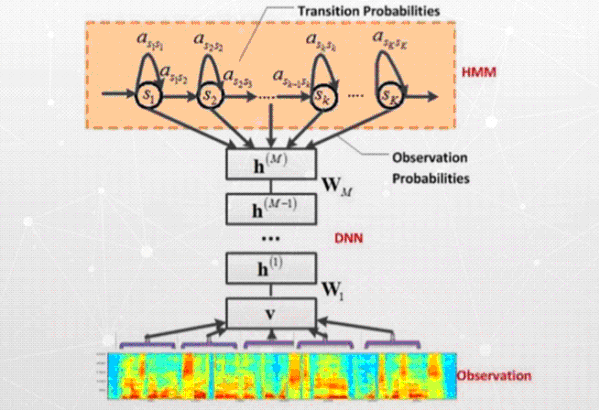
ساختار سرتا سري شبكه هاي عميق بازگشتي
يكي از ساختارهاي معروف شبكه هاي عميق بازگشتي ساختاري همانند تصوير زير دارد كه متعلق به مقاله معروفي است كه چند سال پيش توسط “بايدو” منتشر كرد. باتوجه به تصويري كه در زير مشاهده مي كنيد مرزهاي قبلي را بين دو مدل مختلف قبلي نداريم و تمام اين اتفاقات در شبكه سرتاسري مي افتند، باز هم در اينجا ما expectogram يا ورودي و سپس يك شبكه عميق بازگشتي را داريم. در واقع هم آواها (مدل آگوستيكي) را داريم و در واقع مدل آكوستيكي را آموزش ميبينم و همزمان شبيه سازي زماني را نيز انجام ميدهيم.
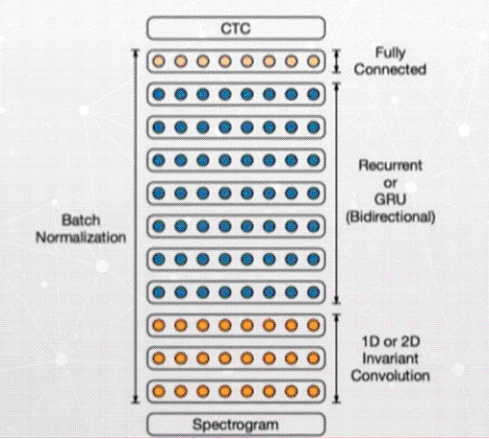
بازشناسايي گفتار با روش هاي يادگيري عميق
در اين روش ما در واقع مي خواهيم تمام مراحل قبلي كه گفته شد را با يك شبكه جايگزين كنيم، يعني سيگنال ورودي داخل يك شبكه اي شود و در نهايت خروجي آن سيگنال را به صورت متن داشته باشيم، بدون اينكه نياز باشد آن سيگنال را به مدل هاي مختلف بشكانيم و استخراج ويژگي كنيم و… و در واقع مي خواهيم يك شبكه سرتاسري در ميانه داشته باشيم.
فارس آوا، نرم افزاري كه گفتار را به نوشتار تبديل مي كند
در حال حاضر در كشور نرم افزاري براي تبديل گفتار به متن وجود دارد كه به كمك روش هايي كه در بالا گفته شد،گفتار را به متن تبديل مي كند.فارس آوا داراي بزرگترين ديتاست فارسي در داخل كشور مي باشد كه شامل 10 هزار ساعت ديتاي زبان فارسي مي باشد. فارس آوا عمليات بازشناسايي گفتار را به كمك روش هاي يادگيري عميق انجام مي دهد و اين نرم افزار تبديل گفتار به متن در زبان فارسي امكان ارتباط كلامي انسان با كامپيوتر و يا موبايل را فراهم مي كند. اين نرم افزار با تكيه بر دانش متخصصان هوش مصنوعي ايراني و با بهره گيري از آخرين تكنولوژي هاي روز دنيا توليد شده است و به دليل جمع آوري بزرگ ترين ديتاست موجود در زبان فارسي و تمركز ويژه روي اين زبان، ضمن بهره مندي از تنوع گفتاري بسيار وسيع موفق شده تا در رقابت با شركت هاي بزرگي چون گوگل ضريب دقت بالايي داشته باشد.
ويژگي ها و قابليت هاي فارس آوا عبارتند از:
·تبديل گفتار به متن فارسي با دقت و سرعت بالا
·بهره مندي از آخرين تكنولوژيهاي يادگيري عميق
·تبديل گفتار به متن بصورت همزمان (Real-Time)
·تشخيص گفتار و صوت در محيط هاي نويزي
·پشتيباني از انواع لهجه ها و گويش ها
·قابليت تبديل گفتار محاوره اي به متن
·پشتيباني از انواع فرمتهاي صوتي و ويديويي
·تبديل گفتار انگليسي به متن انگليسي
·غير وابسته به گوينده و عدم نياز به آموزش براي هر فرد
·توسعه و توليد بصورت كاملاً بومي در داخل كشور
·ارائه API و SDK تبديل گفتار به متن در قالب وب سرويس
·ارائه پنل تحت وب براي آپلود كردن فايلها جهت پردازش
·قابل نصب روي سرور مشتري و عدم نياز اتصال به اينترنت
·بهره مندي از دايره واژگان (فرهنگ لغت) بسيار وسيع
همه ي مواردي كه گفته شد باعث شده تا فارس آوا به يكي از كاربردي ترين و با كيفيت ترين محصولات موجود در بازار امروز ايران، تبديل شود.فارس آوا نرم افزاري است كه به صورت اختصاصي براي زبان فارسي توليد شده است و واژگان زبان فارسي را به خوبي درك و پردازش مي كند.شما مي توانيد با خيالي آسوده از نرم افزار فارس آوا استفاده كنيد و راندمان و بهره وري كار خود و يا كارمندان در سازمان و يا كسب و كارتان را افزايش دهيد. علاوه بر اين ها فارس آوا از رابط كاربري بسيار ساده اي برخوردار است كه اين امر استفاده همه ي افراد از اين نرم افزار را بسيار ساده مي كند.
براي خريد محصول فارس آوا و يا درخواست دمو محصول به اينجا مراجعه كنيد.